mysql存储结构
Mysql 采用B+树的存储结构,这时一颗多路平衡树,由于是多路,所以可以降低树高,但是我们的MySQL还是不满意,觉得效率还不是不够高,于是MySQL 就使用B树的变形也就是B+树,我们在前面就知道B+树有一些特点:真实的数据都是保存在叶子节点上的,非叶子结点只是起到一个导航的作用,并且叶子结点是使用双向链表进行连接的,所以在数据库进行范围查找的时候十分方便.
B树示例:
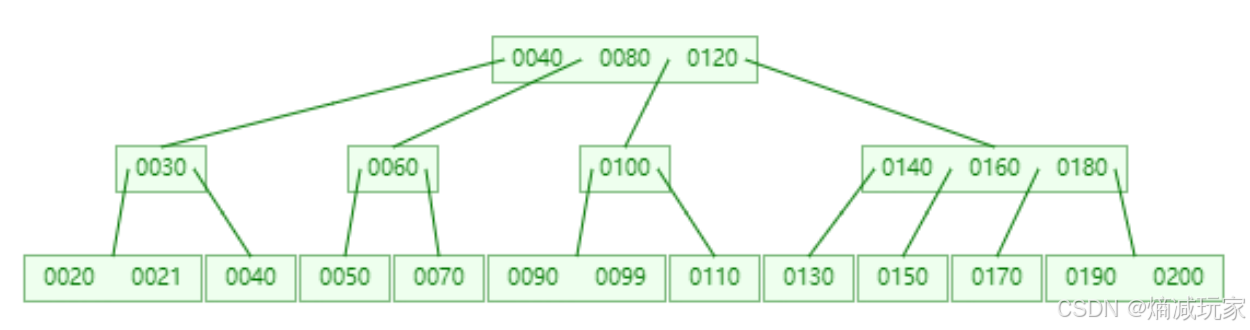
B+树示例:

注意:MySQL 索引使用 B+ 树结构,在 B+ 树基础上使用的是双向指针连接叶结点
mysql 的页
在 .ibd 文件中最重要的结构体是 **Page(页)**,页是内存与磁盘交互最小单元,默认大小是 16KB

每一个.ibd 文件由页组成
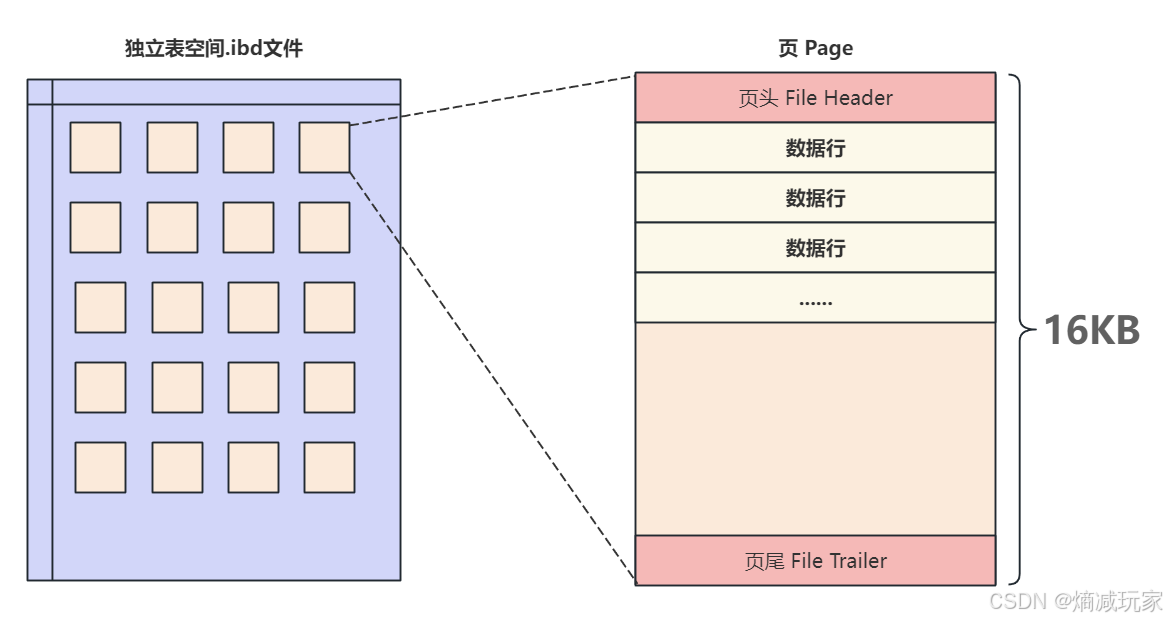
每次内存与磁盘的交互至少读取一页,所以在磁盘中每个页内部的地址都是连续的,之所以这么做,是因为在使用数据的过程中,根据局部性原理,将来要使用的数据大概率与当前访问的数据在空间上是临近的所以一次从磁盘中读取一页的数据放入内存中,当下次查询的数据还在这个页中的时候,就可以直接从内存中读取,从而减少磁盘IO,以此来提高性能。
局部性原理:
是指程序在执行时呈现出局部性规律,在一段时间内,整个程序的执行仅限于程序中的某⼀部
分。相应地,执行所访问的存储空间也局限于某个内存区域,局部性通常有两种形式:时间局部
性和空间局部性。
时间局部性(Temporal Locality):如果⼀个信息项正在被访问,那么在近期它很可能还会被再
次访问。
空间局部性(Spatial Locality):将来要用到的信息大概率与正在使用的信息在空间地址上是临
近的。
每一个页中即使没有数据也会使用 16KB 的存储空间,同时与索引的B+树中的节点对应
我们可以查询MySQL中页的大小:
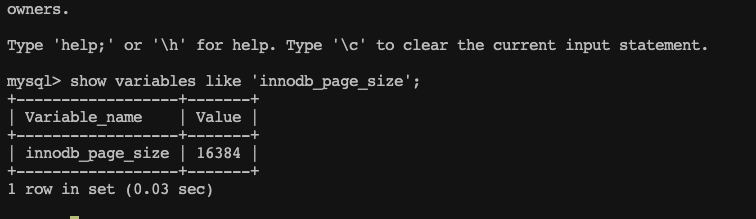
18384 / 1024 = 16 KB
数据页
数据库由很多种的页,索引页、数据页等等,这里我们讨论数据页
页头页尾
数据页的页头和页尾
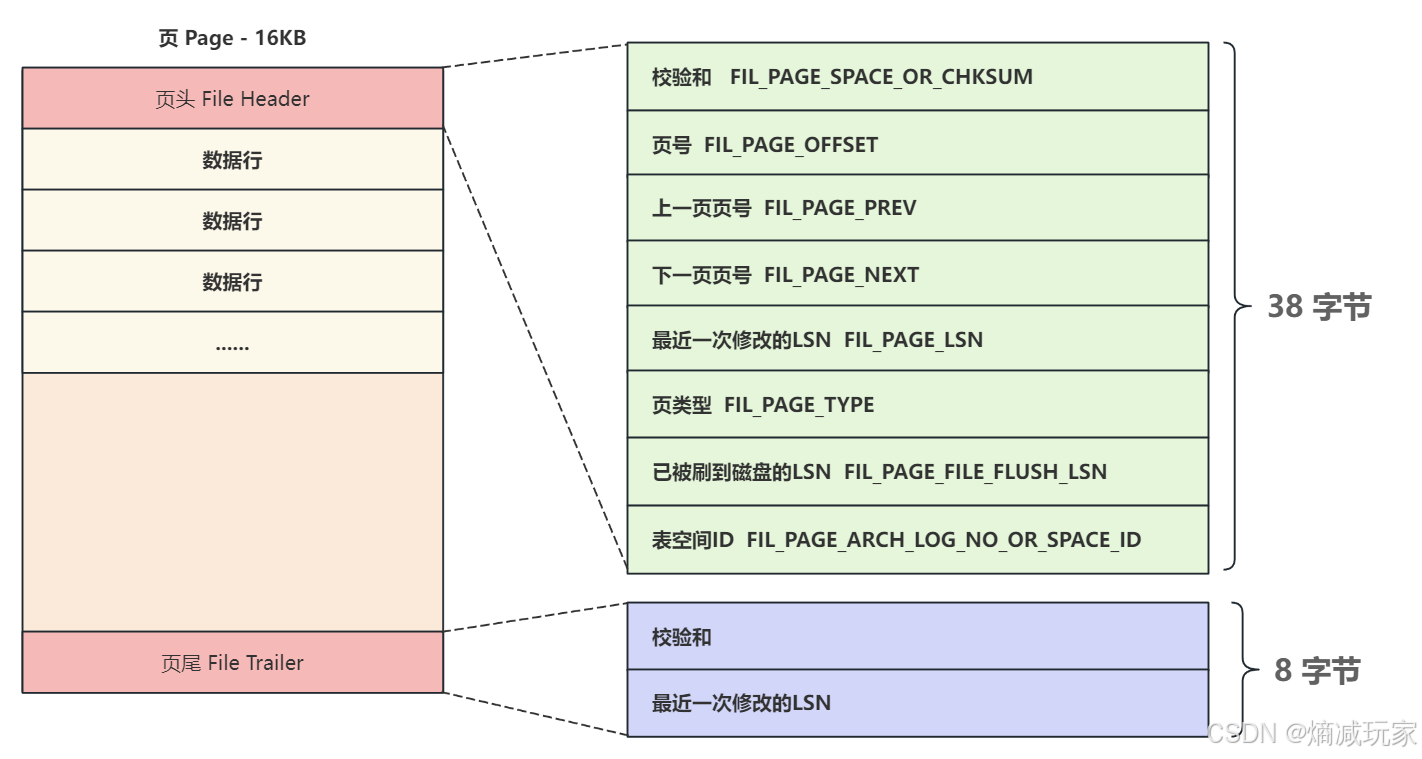
这里我们关注的是页头里包含上一页页号和下一页页号,通过这两个属性可以把页与与之间链接起来,形成一个双向链表。
页主体
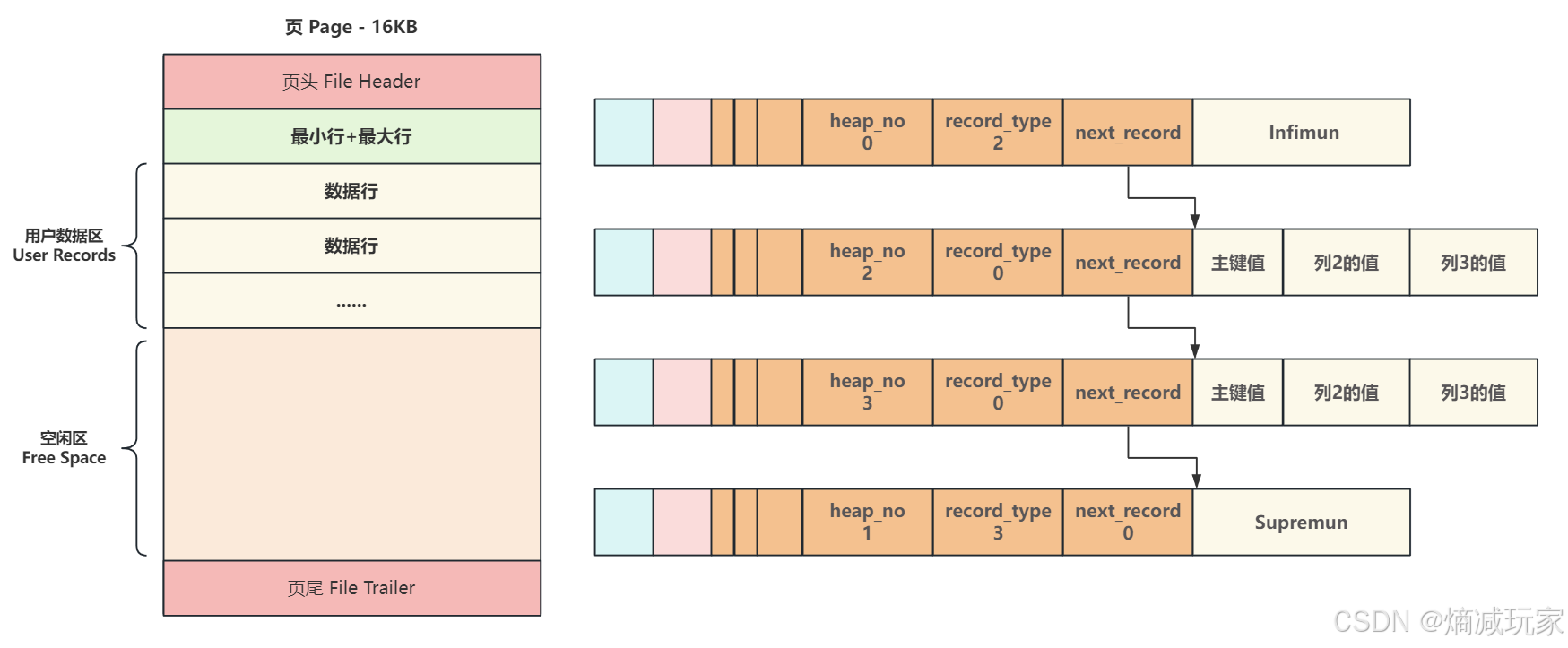
页主体部分是保存真实数据的主要区域,每当创建一个新页时,都会自动分配两个行,一个是页内最小行Infinum,另一个是页内最大行Supremun,这两行并不存储任何真实数据,而是最为数据行链表的头和尾【你可以理解为链表的两个空节点,一个是空的头节点,另一个是空的尾节点】
第一个数据行有一个记录下一行的地址偏移量的区域next_record将页内所有的数据行组成了一个单向链表

当向一个新页插入数据时,将Infimun 连接第一个数据行,最后一行真实数据连接Supremun,这样数据行就构成了一个单向链表,当更多的数据行插入之后,会按照主键从小到大的顺序进行连接:
页目录
看到这里, 是不是又疑惑,单向链表的查找效率不是很慢吗?时间复杂度是O(N),当然开发数据库的人也想到了,为了提高查找效率,InnoDB采用二分查找来解决查询效率问题,于是他们开发了页目录:

具体的实现方式是,在每一个页中加入一个叫做页目录的结构,将页内包括最大行和最小行在内的数据行进行分组,这里单独约定最小行独自为一组,其他分组最多8条数据,同时将最大行放在最后一个分组中,按照主键从小到大的顺序记录在页目录中,页目录每一个位置称为槽,每一个槽对应一个分组,一旦分组中数据行超过8个的时候,就会分裂出一个新的分组
在后续查找某条数据行时,通过二分查找,就可以找到对应的槽,然后在槽对应的分组中进行最多8条数据的便即可获得目标数据
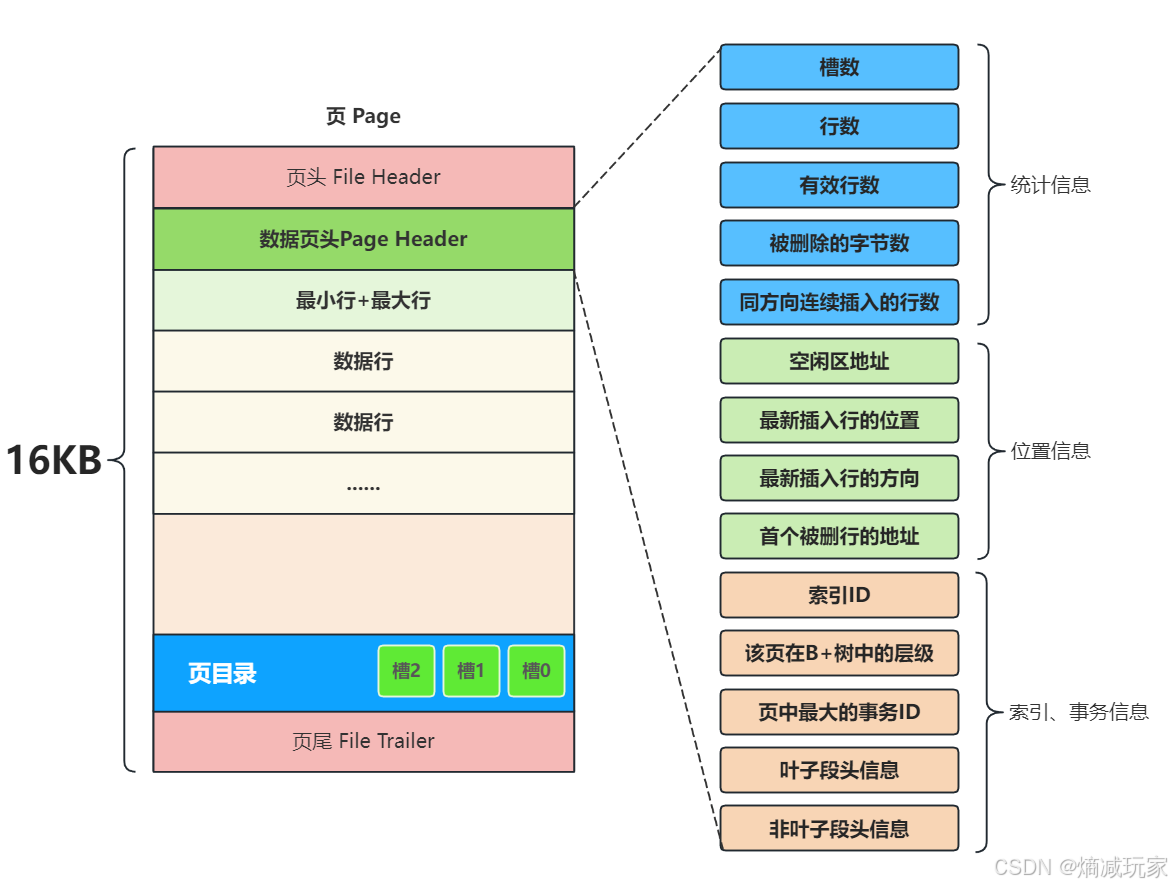
数据页头
数据页头记录了当前页保存数据相关的信息
B+树在数据库中的应用
非叶子节点保存索引数据,叶子节点保存真实数据
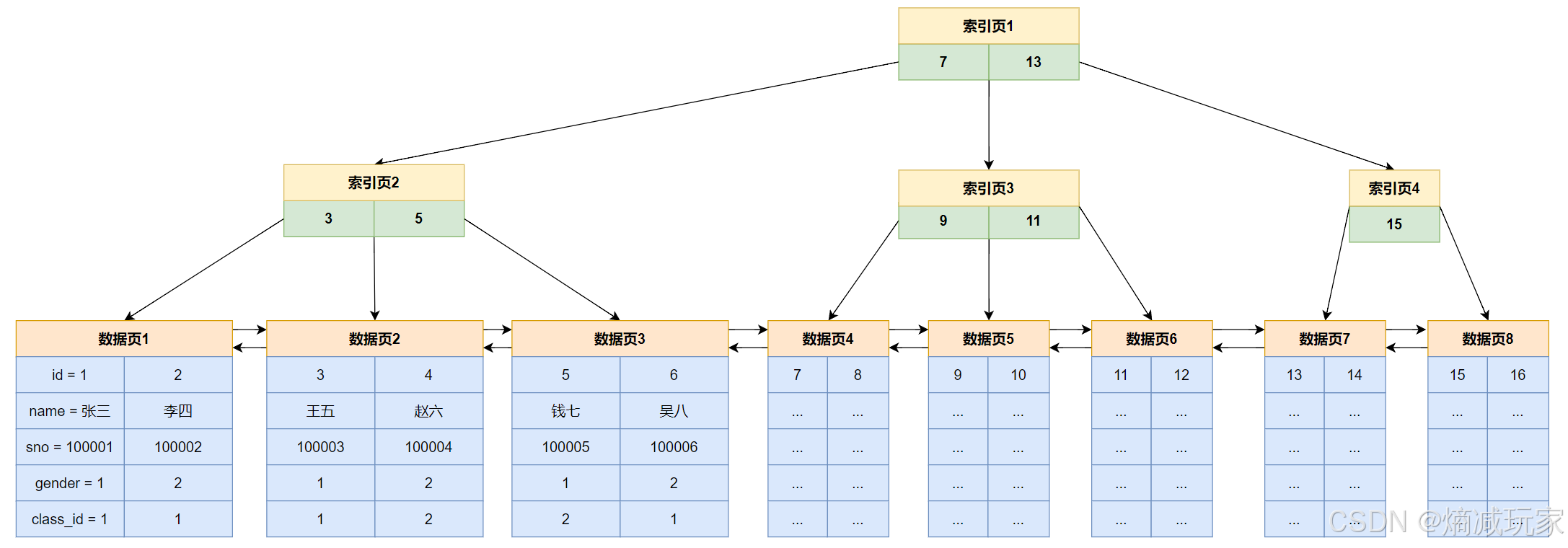
举个例子:查找 id 为7 的数据行,首先通过索引页1,发现 7 = 7 ,进入到索引页2,然后 7 < 9,进入到数据页4,最后找到id 为 7 的数据行,一共进行了三次磁盘IO。
以上的IO过程,加载索引页1–>加载索引页2–>加载数据页3
假设一条数据大小为 1KB,忽略数据页中页头页尾等等非真实数据的内容,也就是说一个数据页可以保存16条数据。
索引页保存的是索引,这里我们以主键索引为例,索引页保存主键值和下一页的地址,主键用bigint 来保存,也就是8字节,地址为6字节,一共就是14字节,页的大小为16KB,那么一个索引页可以保存 16 * 1024 / 14 = 1170 条索引记录
如果B+树树高为三层的话,一条索引记录对应一个数据页,那么三层B+树就可以保存 1170 * 1170 * 16 = 21,902,400 条数据(第一层一个结点,有1170 条索引,那么第二层就有1170个结点,第二层每个结点都有1170条索引),也就是说如果是在两千多万条数据的表中,我们通过三次IO 就可以完成数据的检索了。