shardingshphere数据库分片
概述
Apache ShardingSphere 是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。
Apache ShardingSphere 设计哲学为 Database Plus,旨在构建异构数据库上层的标准和生态。 它关注如何充分合理地利用数据库的计算和存储能力,而并非实现一个全新的数据库。 它站在数据库的上层视角,关注它们之间的协作多于数据库自身。
ShardingShpere的两个核心模块:
ShardingSphere-JDBC:ShardingSphere-JDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。
ShardingSphere-Proxy:ShardingSphere-Proxy 定位为透明化的数据库代理端,通过实现数据库二进制协议,对异构语言提供支持。
在开发中实现分库分表的操作,我们一般使用的ShardingSphere-JDBC这个模块。
ShardingSphere的分库分表操作的逻辑图:
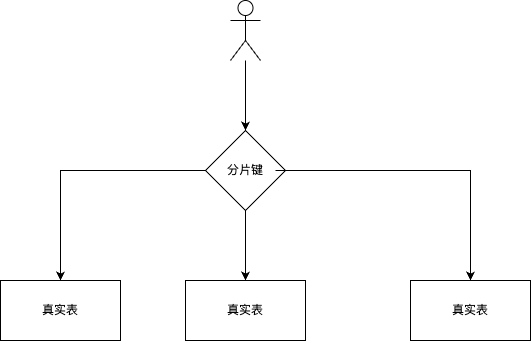
开发者配置了分库分表策略后,我们只需要操作逻辑表名就可以了。
数据分片带来的优缺点
数据分片主要是用来解决海量的数据访问的问题,将数据库采用垂直拆分或者水平拆分的方式将海量、复杂的数据分布到不同的数据库、数据表中,以此来实现专库专用、提高访问性能。
优点
- 提高可扩展性:通过将数据拆分成多个小型数据库,每个数据库仅处理一部分数据,可以在数据增长时动态地添加新的分片,从而提高整个系统的可扩展性。
- 提升性能:分片后的每个小型数据库只处理部分数据,减轻了单个节点的压力,从而提升了整个系统的性能。
缺点
复杂性增加:数据分片意味着需要更多的数据库来存储和管理数据,这增加了系统的复杂性。同时,对于每个查询,可能需要跨多个数据库进行查找,增加了查询的复杂性。
并发控制:在分布式系统中,并发控制是一个重要的问题。如果多个节点同时更新同一片数据,就可能导致数据不一致的问题。因此,需要采用并发控制技术来保证数据的正确性。
数据迁移和恢复:当新增或删除分片时,需要进行数据迁移和恢复。这个过程可能会导致数据的不一致或丢失。因此,需要设计合理的迁移和恢复策略来保证数据的正确性。
我们所使用ShardingSphere组件,通过配置Yaml文件来降低我们的编码复杂度。并发控制何数据迁移与恢复都是需要其他的方式来解决。
ShardingSphere分表操作
ShardingSphere的分库分表操作都是基于ShardingSphere-JDBC这个模块来实现。在当前开发中一般都需要和Springboot进行整合,而且只要是流行的框架、组件,SpringBoot一般都会有一个集成的依赖。
分片和读写分离请看该分类其他文档.